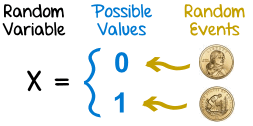Nice clear explanation of the difference. This should be given in every statistical/probability course.
In probability, we start with a model describing what events we think are going to occur, with what likelihoods. The events may be random, in the sense that we don’t know for sure what will happen next, but we do quantify our degree of surprise when various things happen.
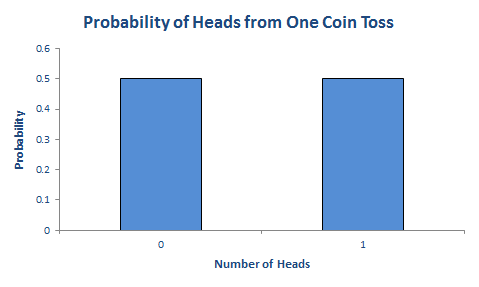
The standard (maybe overused) example is flipping a fair coin. “Fair” means, technically, that the probability of heads on a given flip is 50%, and the probability of tails on a given flip is 50%. This doesn’t mean that every other flip will give a head — after all, three heads in a row is no surprise. Five heads in a row would be more surprising, and when you’ve seen twenty heads in a row you’re sure that something fishy is going on. What the 50% probability of heads does mean is that, as the number of flips increases, we expect the number of heads to approach half the number of flips. Seven heads on ten flips is no surprise; 700,000 heads on 1,000,000 tosses is highly unlikely.
Another example would be flipping an unfair coin, where we know ahead of time that there’s a 60% chance of heads on each toss, and a 40% chance of tails.
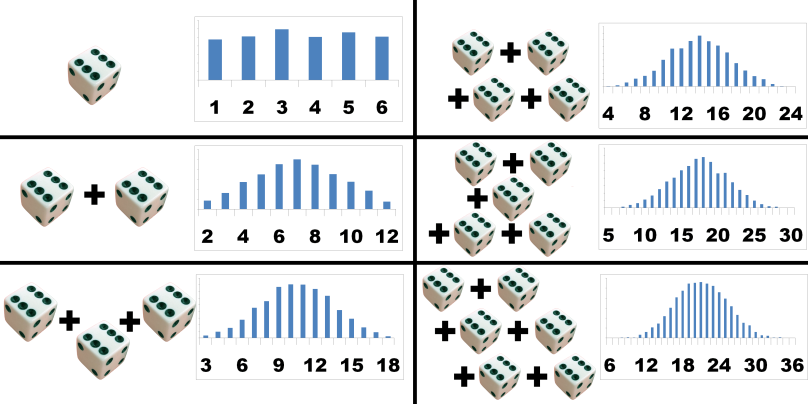
A third example would be rolling a loaded die, where (for example) the chances of rolling 1, 2, 3, 4, 5, or 6 are 25%, 5%, 20%, 20%, 20%, and 10%, respectively. Given this setup, you’d expect rolling three 1’s in a row to be much more likely than rolling three 2’s in a row.
As these examples illustrate, the probabilist starts with a probability model (something which assigns various percentage likelihoods of different things happening), then tells us which things are more and less likely to occur.
Key points about probability:
- Rules → data: Given the rules, describe the likelihoods of various events occurring.
- Probability is about prediction — looking forward.
- Probability is mathematics.
The statistician turns this around:
- Rules ← data: Given only the data, try to guess what the rules were. That is, some probability model controlled what data came out, and the best we can do is guess — or approximate — what that model was. We might guess wrong; we might refine our guess as we get more data.
- Statistics is about looking backward.
- Statistics is an art. It uses mathematical methods, but it is more than math.
- Once we make our best statistical guess about what the probability model is (what the rules are), based on looking backward, we can then use that probability model to predict the future. (This is, in part, why I say that probability doesn’t need statistics, but statistics uses probability.)
Here’s my favorite example to illustrate. Suppose I give you a list of heads and tails. You, as the statistician, are in the following situation:
- You do not know ahead of time that the coin is fair. Maybe you’ve been hired to decide whether the coin is fair (or, more generally, whether a gambling house is committing fraud).
- You may not even know ahead of time whether the data come from a coin-flipping experiment at all.
Suppose the data are three heads. Your first guess might be that a fair coin is being flipped, and these data don’t contradict that hypothesis. Based on these data, you might hypothesize that the rules governing the experiment are that of a fair coin: your probability model for predicting the future is that heads and tails each occur with 50% likelihood.
If there are ten heads in a row, though, or twenty, then you might start to reject that hypothesis and replace it with the hypothesis that the coin has heads on both sides. Then you’d predict that the next toss will certainly be heads: your new probability model for predicting the future is that heads occur with 100% likelihood, and tails occur with 0% likelihood.
If the data are “heads, tails, heads, tails, heads, tails”, then again, your first fair-coin hypothesis seems plausible. If on the other hand you have heads alternating with tails not three pairs but 50 pairs in a row, then you reject that model. It begins to sound like the coin is not being flipped in the air, but rather is being flipped with a spatula. Your new probability model is that if the previous result was tails or heads, then the next result is heads or tails, respectively, with 100% likelihood.